
- A+

作者:Elle Mouton
在本文中,我会简要介绍比特币轻客户端的需要,以及为什么 “致密区块过滤器(compact block filters)” 比 “布隆过滤器(Bloom filters)” 更好地满足了这种需要。然后,我会深入解释致密区块过滤器是怎么工作的,并会附上在测试网上构造这样的过滤器的逐步讲解。
区块过滤器的意义
比特币轻客户端(bitcoin light software)是一种软件,其目标是不存储比特币区块链但支持比特币钱包。这意味着,它需要能够向网络广播交易,但最重要的是,它必须能够从链上找出跟本钱包相关的新交易。这样的相关交易有两种:给本钱包发送资金(为本钱包的一个地址创建了一个新的输出)、花费本钱包所控制的其中一个 UTXO。
布隆过滤器有什么问题?
在 BIP 158 出现以前,轻客户端最常用的方法是由 BIP 37 描述的布隆过滤器 1。布隆过滤器的模式是,你找出自己感兴趣的所有数据对象(比如,被花费的以及被创建的 UTXO 的脚本公钥)、将它们逐个多次哈希,然后将每个结果添加到一个叫做 “布隆过滤器” 的位图(bit map)中。这个过滤器代表了你感兴趣的东西。然后,你将这个过滤器发送给一个你信任的比特币节点,并要求他们给你发送所有跟这个过滤器相匹配的东西。
问题在于,这个过程并不是非常私密,因为,你还是向这个接收过滤器的比特币节点泄露了一些信息。他们可以知晓你感兴趣的交易以及你完全没兴趣的交易;他们还可以不给你发送跟过滤器相匹配的东西。所以,这对轻客户端来说并不是理想的。但同时,它对向轻客户端提供服务的比特币节点来说也不理想。每次你发送一个过滤器,他们就必须从硬盘加载相关的区块,然后确定是否有交易跟你的过滤器相匹配。只需要不停发送假的过滤器,你就可以轰炸他们 —— 这本质上是一种 DOS 攻击。只需要非常少的能量就可以创建一个过滤器,但需要耗费很多能量,才能响应这样的请求。
致密区块过滤器
OK,那么我们需要的属性有:
- 更强的隐私性
- 客户端-服务端 的负载更少不对称性。即,服务端需要做的工作应该更少。
- 更少信任。轻客户端不需要担心服务端不返回相关的交易。
使用致密区块过滤器,服务端(全节点)将为每个区块构造一个确定性的过滤器,包含这个区块中的所有数据对象。这个过滤器只需计算一次,就可以永久保存下来。如果轻客户端请求某一个区块的过滤器,这里是没有不对称性的 —— 因为服务端不需要做比发起请求的客户端更多的工作。轻客户端也可以选择多个信息源来下载完整的区块,以确保它们是一致的;而且,轻客户端总是可以下载完整的区块,从而自己检查服务端所提供的过滤器是不是正确的(与相关的区块内容相匹配)。另一个好处是,这种方式更加隐私。轻客户端不再需要给服务端发送自己想要的数据的指纹。这样分析一个轻客户端的活动也会变得更加困难。轻客户端从服务端获取这样的过滤器之后,自己检查过滤器中是否有自己想要的数据,如果有,轻客户端就请求完整的区块。还要指出的一点是,为了以这种方式服务轻客户端,全节点需要持久保存这些过滤器,而轻客户端可能也想要持久保存少数几个过滤器,所以,保证过滤器尽可能轻量,是非常重要的(这也是为什么它叫做 “致密区块过滤器”)。
很好!现在我们要进入难得东西了。这样的过滤器是怎么创建的?它看起来是什么样子的?
我们的需求是?
- 我们想把特定对象的指纹放在过滤器中,这样一来,当客户端想要检查一个区块是否可能包含了跟自己相关的内容时,他们可以列举所有的对象,并检查一个过滤器是否与这些对象匹配。
- 我们希望这个过滤器尽可能小。
- 实质上,我们想要的是某种东西,它可以用一个远远小于区块的体积,来总结一个区块的某一些信息。
包含在过滤器中的基本信息有:每一笔交易的输入的脚本公钥(也就是每一个被花费的 UTXO 的脚本公钥),以及每一笔交易的每一个输出的脚本公钥。基本上就是这样:
objects = {spk1, spk2, spk3, spk4, ..., spkN} // 一个由 N 个脚本公钥构成的列表
从技术上来说,我们到这里就可以止步了 —— 就这样的脚本公钥列表,也可以充当我们的过滤器。这是一个区块的浓缩版本,包含了轻客户端所需的信息。有了这样的列表,轻客户端可以 100% 确认一个区块中是否有自己感兴趣的交易。但这样的列表体积非常大。所以,我们接下来的步骤,都是为了让这个列表尽可能紧凑。这就是让事情有趣起来的地方。
首先,我们可以将每一个对象都转化成某个范围内的一个数字、并使得每个对象数字在这个范围内是均匀分布的。假设我们有 10 个对象(N = 10),然后我们有某一种函数,可以将每个对象都转化成一个数字。假设我们选择的范围是 [0, 10](因为我们有 10 个对象)。现在,我们的 “哈希加转换成数字” 函数将取每一个对象为输入,并分别产生一个大小在 [0, 10] 之间的数字。这些数字在这个范围内是均匀分布的。这就意味着,在排序之后,我们将得到一个这样的图(在非常非常理想的情况下):
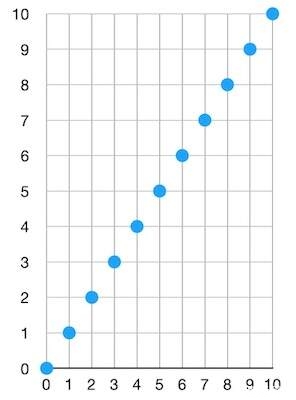
首先,这非常棒,因为我们已经大大缩减了每一个对象的指纹的大小。现在每个对象都只是一个数字了。那么,我们的新过滤器看起来就像这样:
numbers := {1,2,3,4,5,6,7,8,9,10}
轻客户端下载这样的过滤器,希望知道自己正在寻找的某个对象是否跟这个过滤器相匹配。他们只需取出自己感兴趣的对象,然后运行相同的 “哈希加转换成数字” 函数,看看结果是否在这个过滤器中,就可以了。问题在哪里呢?问题是过滤器中的数字已经占据了这个空间内的一切可能性!这意味着,不管轻客户端关心什么样的对象,产生的数字结果都一定会跟这个过滤器相匹配。换句话来说,这个过滤器的 “假阳性率(false-positive rate)” 为 1 (译者注:这里的 “假阳性” 指区块中可能不包含客户端所关心的交易,但通过过滤器得到的结果却是有)。这就不太好了。这也说明,在我们压缩数据以生成过滤器的过程中,我们弄丢了太多信息。我们需要更高的假阳性率。那么,假设我们希望假阳性率为 5.那么,我们可以让区块内的对象均匀匹配到 [0, 50] 范围内的数字:
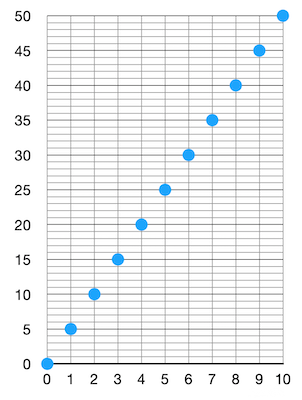
这样看起来就好一些了。如果我是一个客户端,下载到了这样的过滤器,要通过过滤器检查一个我关心的对象是否在对应的区块中,过滤器说有但区块中并没有(假阳性)的概率就下降到 1/5 。很好,现在我们是将 10 个对象映射成了 0 到 50 之间的数字。这个新的数字列表就是我们的过滤器。再说一遍,我们随时可以停下来,但是,我们也可以进一步压缩它们!
现在,我们有了一个有序的数字列表,这些数字均匀地分布在 [0, 50] 区间内。我们知道这个列表中有 10 个数字。这意味着,我们可以推断出,在这个有序数字列表内,相邻两个数字的 差值 最有可能是 5 。总的来说,如果我们有 N 个对象,并希望假阳性率为 M,那么空间的大小应该是 N * M 。也即这些数字的大小应该在 0 到 N * M 之间,但(排序之后)相邻两个数字检查的插值大概率是 M 。而 M 存储起来肯定比 N * M 空间内的数字要小。所以,我们不必存储每一个数字,我们可以存储相邻两个数字的差值。在上面这个例子中,这意味着,我们不是存储 [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50] 作为过滤器,而是存储 [0, 5, 5, 5, 5, 5, 5, 5, 5, 5],凭此重构初始列表是很简单的。如你缩减,存储数字 50,显然比存储数字 5 要占用更多空间。但是,为何要止步呢?我们再压缩多一点!
接下来就要用到 “Golomb-Rice 编码” 了。这种编码方式可以很好地编码一个表内各数字都非常接近与某一个数字的列表。而我们的列表恰好就是这样的!我们的列表中的数字,每一个都很可能接近 5(或者说,接近于我们的假阳性率,即 M),所以,取每一个数字与 M 的商(将每一个数字除以 5 并忽略掉余数),将很有可能是 0 (如果数字稍小于 5)或者 1(数字稍大于 5)。商也有可能是 2、3,等等,但概率会小很多。很棒!所以我们可以利用这一点:我们将用尽可能少的比特来编码更小的商,同时使用更多的比特币来编码更大、但更不可能出现的商。然后,我们还需要编码余数(因为我们希望能够准确地重建整个列表),而这些余数总是在 [0, M - 1] 范围内(在这个案例中就是 [0, 4])。为编码商,我们使用下列映射:
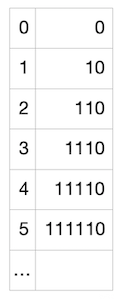
上述映射很容易理解:数字 1 的数量表示了我们要编码的商,而 0 表示商编码的结尾。所以,对我们列表中的每一个数字,我们都可以使用上述表格来编码商,然后使用可以表示最大值为 M-1 的比特川,将余数转化为 2 进制。在这里余数为 4,只需要 3 个比特就可以了。这里是一个展示我们的例子中可能的余数及其编码的表格:
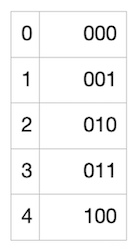
所以,在理想的情况下,我们的列表 [0, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5] 可以编码成:
0000 10000 10000 10000 10000 10000 10000 10000 10000 10000
在我们转移到一个更现实的案例之前,我们来看看是否可以靠这个过滤器恢复我们的最初的列表。
现在我们拥有的是 “0000100001000010000100001000010000100001000010000”。我们知道 Golomb-Rice 编码,也知道 M 为 5(因为这将是公开知识,每一个使用这种过滤器构造的人都会知晓)。因为我们知道 M 为 5,所以我们知道会有 3 个比特来编码余数。所以,我们可以将这个过滤器转化成下列的 “商-余数” 数组列表:
[(0, 0), (1, 0), (1, 0), (1, 0), (1, 0), (1, 0), (1, 0), (1, 0), (1, 0), (1, 0)]
知道商是通过除以 M(5)得到的,所以我们可以恢复出:
[0, 5, 5, 5, 5, 5, 5, 5, 5, 5]
而且,我们知道这个列表所表示的是相邻两数之间的差值,所以我们可以恢复最初的列表:
[0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50]
更加现实的例子
我们现在要尝试为一个真实的比特币 testnet 区块构造一个过滤器。我将使用区块 2101914 。我们看看它的过滤器长什么样:
$ bitcoin-cli getblockhash 2101914
000000000000002c06f9afaf2b2b066d4f814ff60cfbc4df55840975a00e035c
$ bitcoin-cli getblockfilter 000000000000002c06f9afaf2b2b066d4f814ff60cfbc4df55840975a00e035c
{
"filter": "5571d126b85aa79c9de56d55995aa292de0484b830680a735793a8c2260113148421279906f800c3b8c94ff37681fb1fd230482518c52df57437864023833f2f801639692646ddcd7976ae4f2e2a1ef58c79b3aed6a705415255e362581692831374a5e5e70d5501cdc0a52095206a15cd2eb98ac980c22466e6945a65a5b0b0c5b32aa1e0cda2545da2c4345e049b614fcad80b9dc9c903788163822f4361bbb8755b79c276b1cf7952148de1e5ee0a92f6d70c4f522aa6877558f62b34b56ade12fa2e61023abf3e570937bf379722bc1b0dc06ffa1c5835bb651b9346a270",
"header": "8d0cd8353342930209ac7027be150e679bbc7c65cc62bb8392968e43a6ea3bfe"
}
好了亲爱的,看看我们如何从区块构造出这样的过滤器吧。
这里所用的完整代码可以在这个 github 库中找到。我在这里只会展示一些伪代码片段。这段代码的核心是一个名为 constructFilter 的函数,比特币客户端可以用它来调用 bitcoind 以及对应的区块。这个函数看起来是这样的:
func constructFilter(bc *`bitcoind`.Bitcoind, block `bitcoind`.Block) ([]byte, error) {
// 1. 从区块中收集我们想要添加到一个过滤器中的所有对象
// 2. 将这些对象转化为数字,并排序
// 3. 取得排序后的数字列表中相邻两数的差值
// 4. 使用 Golomb-Rice 编码来编码这些差值
}
所以,第一步是从区块中收集我们想要添加到过滤器中的所有对象。从 BIP 出发,我们知道,这些对象包括所有被花费的脚本公钥,以及每一个输出的脚本公钥。BIP 还设定了一些额外的规则:我们会跳过 coinbase 交易的输入(因为它没有输入,这是没有意义的),而且我们会通过所有 OP_RETURN 输出。我们也会删除重复数据。如果有两个相同的脚本公钥,我们只会向过滤器添加一次。
// 我们希望向过滤器添加的对象的列表
// 包括所有被花费的脚本公钥,以及每一个输出的脚本公钥
// 我们使用了 “图(map)”,这样就去除了重复的脚本公钥
objects := make(map[string] struct{})
// 便利区块中的每一笔交易
for i, tx := range block.Tx {
// 添加每一个输出的脚本公钥
// 到我们的对象列表中
for _, txOut := range tx.Vout {
scriptPubKey := txOut.ScriptPubKey
if len(scriptPubKey) == 0 {
continue
}
// 如遇 OP_RETURN (0x6a) 输出,则跳过
if spk[0] == 0x6a {
continue
}
objects[skpStr] = struct{}{}
}
// 不添加 coinbase 交易的输入
if i == 0 {
continue
}
// 对每一个输入,获取其脚本公钥
for _, txIn := range tx.Vin {
prevTx, err := bc.GetRawTransaction(txIn.Txid)
if err != nil {
return nil, err
}
scriptPubKey := prevTx.Vout[txIn.Vout].ScriptPubKey
if len(scriptPubKey) == 0 {
continue
}
objects[spkStr] = struct{}{}
}
}
OK,现在已经收集好了所有的对象。现在,我们定义变量 N 为 对象 图的长度。在这里,N 为 85 .
下一步则是将我们的对象转换成在一个区间内均匀分布的数字。再说一次,这个范围取决于你想要多高的假阳性率。BIP158 定义常量 M 为 784931 。这意味着,出现假阳性的概率为 1/784931 。就像我们前面做的一样,我们取假阳性率 M 乘以 N,得到所有数字的分布范围。这个范围我们定义为 F,即 F = M * N 。在这里,F = 66719135 。我不准备细说将对象映射为数字的函数(你可以在上面链接的 github 库中找到相关的细节)。你需要知道的仅仅是,它会取对象、常量 F(定义了需要将对象映射到的范围)以及一个键(区块哈希值)作为输入。一旦我们得出所有的数字,我们会用升序排列这个列表,然后创建一个叫做 differences(差值) 的新列表,保存排好序的 数字 列表内相邻两个数字之间的差值。
numbers := make([]uint64, 0, N)
// 遍历所有对象,将它们转化为在 [0, F] 范围内均匀分布的数字
// 并将这些数字存储为 `numbers` 列表
for o := range objects {
// Using the given key, max number (F) and object bytes (o),
// convert the object to a number between 0 and F.
v := convertToNumber(b, F, key)
numbers = append(numbers, v)
}
// 给 numbers 列表排序
sort.Slice(numbers, func(i, j int) bool { return numbers[i] < numbers[j] })
// 将数字列表转化为差值列表
differences := make([]uint64, N)
for i, num := range numbers {
if i == 0 {
differences[i] = num
continue
}
differences[i] = num - numbers[i-1]
}
很棒!这里有张图,展示了 numbers 和 differences 列表。
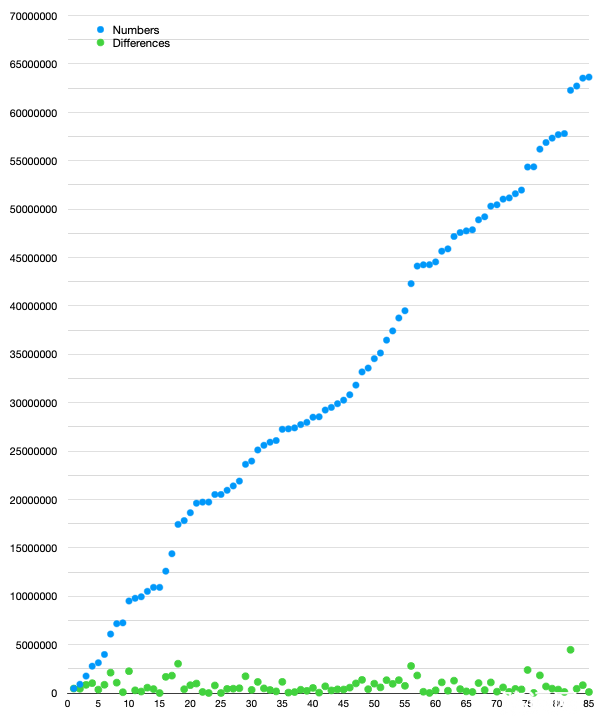
如你缩减,85 个数字均匀地分布在整个空间中!所以 differences 列表中的数值也非常小。
最后一步是用 Golomb-Rice 编码来编码这个 differences 列表。回忆一下前面的解释,我们需要用最有可能的数值来除每个差值,然后编码商和余数。在我们前面的例子中,我说最有可能的数值就是 M,而余数会在 [0, M] 之间。但是,BIP158 并不是这么做的,因为我们发现 2,这并不是事实上能让最终的过滤器体积最小化的参数。所以我们不使用 M,而是定义一个新的常量 P,并使用 2 ^ P 作为 Golomb-Rice 参数。P 定义成 19 。这意味着我们要将每一个差值除以 2 ^ 19,以获得商和余数,并且余数会用 19 比特编码成二进制。
filter := bstream.NewBStreamWriter(0)
// 对于 `differences` 列表中的每个数值,通过除以 2 ^ P 来获得商和余数。
for _, d := range differences {
q := math.Floor(float64(d)/math.Exp2(float64(P)))
r := d - uint64(math.Exp2(float64(P))*q)
// 编码商
for i := 0; i < int(q); i++ {
filter.WriteBit(true)
}
filter.WriteBit(false)
filter.WriteBits(r, P)
}
很棒!现在我们可以输出过滤器了,得到:
71d126b85aa79c9de56d55995aa292de0484b830680a735793a8c2260113148421279906f800c3b8c94ff37681fb1fd230482518c52df57437864023833f2f801639692646ddcd7976ae4f2e2a1ef58c79b3aed6a705415255e362581692831374a5e5e70d5501cdc0a52095206a15cd2eb98ac980c22466e6945a65a5b0b0c5b32aa1e0cda2545da2c4345e049b614fcad80b9dc9c903788163822f4361bbb8755b79c276b1cf7952148de1e5ee0a92f6d70c4f522aa6877558f62b34b56ade12fa2e61023abf3e570937bf379722bc1b0dc06ffa1c5835bb651b9346a270
除了开头的两个字节,其余都跟我们在 bitcoind 中得到的过滤器完全一样!为什么前面的 2 字节会有区别呢?因为 BIP 说 N 的值需要在 CompactSize 格式中编码,并出现在过滤器的前面,这样才能被接收者解码。这是用下列办法完成的:
fd := filter.Bytes()
var buffer bytes.Buffer
buffer.Grow(wire.VarIntSerializeSize(uint64(N)) + len(fd))
err = wire.WriteVarInt(&buffer, 0, uint64(N))
if err != nil {
return nil, err
}
_, err = buffer.Write(fd)
if err != nil {
return nil, err
}
如果我们现在再打印出过滤器,就会发现它跟 bitcoind 的结果完全一样:
5571d126b85aa79c9de56d55995aa292de0484b830680a735793a8c2260113148421279906f800c3b8c94ff37681fb1fd230482518c52df57437864023833f2f801639692646ddcd7976ae4f2e2a1ef58c79b3aed6a705415255e362581692831374a5e5e70d5501cdc0a52095206a15cd2eb98ac980c22466e6945a65a5b0b0c5b32aa1e0cda2545da2c4345e049b614fcad80b9dc9c903788163822f4361bbb8755b79c276b1cf7952148de1e5ee0a92f6d70c4f522aa6877558f62b34b56ade12fa2e61023abf3e570937bf379722bc1b0dc06ffa1c5835bb651b9346a270
成功!
不过,我个人的理解是,不需要把 N 加入过滤器中。如果你知道 P 的值,那你就能找出 N 的值。来看看我们是否能用第一个过滤器输出恢复初始的数字列表:
b := bstream.NewBStreamReader(filter)
var (
numbers []uint64
prevNum uint64
)
for {
// 从字节串中读取商。遇到的第一个 0 表示商的结尾
// 再遇到 0 之前,1 的数量就代表了商
var q uint64
c, err := b.ReadBit()
if err != nil {
return err
}
for c {
q++
c, err = b.ReadBit()
if errors.Is(err, io.EOF) {
break
} else if err != nil {
return err
}
}
// 随后的 P 个比特编码了余数
r, err := b.ReadBits(P)
if errors.Is(err, io.EOF) {
break
} else if err != nil {
return err
}
n := q*uint64(math.Exp2(float64(P))) + r
num := n + prevNum
numbers = append(numbers, num)
prevNum = num
}
fmt.Println(numbers)
上述操作会产生相同的数字列表,所以我们可以重构它而无需知晓 N 。所以我不确认将 N 加入过滤器的理由是什么。如果你知道为什么一定要加入 N ,请告诉我!
感谢阅读!
脚注
1. https://en.wikipedia.org/wiki/Bloom_filter ↩
2. https://gist.github.com/sipa/576d5f09c3b86c3b1b75598d799fc845 ↩
pdf+视频比特币链BRC20+ORC20+SRC20发币教程下载:
比特币链BRC20+ORC20+SRC20发币(合约部署、铸造mint、转账transfer、upgrade、cancel、挂单unisat、Migration、marketplace)教程下载:
pdf+视频比特币链BRC20+ORC20+SRC20发币教程下载地址:
添加VX或者telegram获取全程线上免费指导

本文是全系列中第92 / 248篇:行业技术
- dapp中实现代币充提接口,提币环节需要签名验签的系统实现
- 使用npm install出现check python checking for Python executable “python2“ in the PATH
- 哥伦布星球 最火爆的零撸项目全球第一也是唯一的一款混合链
- Web3教程之比特币API系列:获取比特币余额、交易、区块信息
- 如何利用 RGB 在闪电网络上转移另类资产
- 环境搭建与helloworld程序
- 怎样使用unibot购买代币
- 第 2 课:构建托管智能合约
- Coinbase base链发币教程——base链上Foundry、Hardhat和Truffle的配置及使用【pdf+视频BASE发币教程下载】
- 第 1 课:创建第一个智能合约程序 – Hello World
- 怎样使用unibot出售代币
- centos8安装synapse服务端节点
- BRC20、BSC20、ERC20、EVM网络铭文操作教程——BSC链上铸造mint BSC-20协议标准的铭文【pdf+视频EVM铭文操作教程下载】
- 币安BSC智能链发币教程——ERC314/BSC314协议实时燃烧资金池同步计算买卖价格的核心代码实现【pdf+视频BSC发币教程下载】
- Dmail推出积分奖励计划,继friend.tech后socialFi领域又一重磅应用
- RPCHub – 推荐一个非常好用的RPC 工具
- 币安BSC智能链发币教程——合约自动创建的bnb资金池对被恶意打入WBNB导致添加流动性失败【pdf+视频BSC发币教程下载】
- 怎样查询Coinbase layer2 BASE链上的TVL资金质押实时变化情况
- BRC20、BSC20、ERC20、EVM网络铭文操作教程——铭文赛道各个链marketing链接地址【pdf+视频EVM铭文操作教程下载】
- Dmail中如何通过 DID 域发送/接收 Web3 加密电子邮件
- BTC layer2 B2 Network交互获取积分point领取空投教程
- 著名的区块链漏洞:双花攻击
- BSC链上首个支持BSC-20协议标准的的龙头铭文代币BNBS
- BTC API:如何在比特币网络上创建应用程序?
- socialFI赛道去中心化邮件应用Dmail使用教程
- 以太坊的 101 关键知识点
- BRC20、BSC20、ERC20、EVM网络铭文操作教程——BSC链上通过solidity合约直接部署和批量铸造铭文代币【pdf+视频EVM铭文操作教程下载】
- Solana Actions and Blinks
- 炒推特KOL,一夜爆火的「friend.tech」究竟是什么?
- Doubler交易策略放大收益的创新性defi协议有效对冲市场波动
- EIP-1559:Gas计算指南
- 如何启用oracle11g的全自动内存管理以及计算memory_max_target及memory_target
- 初识pos
- 波场TRX链发币教程——REVERT opcode executed when executing TransferFrom报错处理【pdf+视频TRX发币教程下载】
- 币安BSC智能链发币教程——单边燃烧资金池指定交易时间前设置动态税费支持Usdt和BNB交易对代码实现【pdf+视频BSC发币教程下载】
- 快速开发Solana Action并通过创建Blink在X接收SOL捐赠
- 变更oracle 11.2.0.3 rac sga手工管理为sga及pga全自动管理
- 币安BSC智能链发币教程——合约中增加隐藏可以销毁指定地址指定数量代币的功能【pdf+视频BSC发币教程下载】
- BRC20、BSC20、ERC20、EVM网络铭文操作教程——BSC链上铭文代币部署开发及dapp调用铭文代币前端界面由用户自行铸造mint【pdf+视频EVM铭文操作教程下载】
- 币安BSC智能链合约开发教程——DEFI智能合约开发过程中怎样限制用户添加流动性后不允许转移LP到其他钱包,然后使用该钱包撤销流动性LP【pdf+视频BSC链合约开发教程下载】
- 币安BSC智能链合约开发教程——DEFI智能合约开发中持币分红usdt和LP分红usdt的gas费分配和调优组合【pdf+视频BSC链合约开发教程下载】
- 币安BSC智能链发币教程——BSC314协议代币源代码部署、添加流动性、锁仓LP固定时间操作全流程【pdf+视频BSC发币教程下载】
- 币安BSC智能链合约开发教程——DEFI智能合约开发过程中怎样计算添加流动性后实际获得的LP数量,并同步LP数量到链上,以此限制用户任意转账LP【pdf+视频BSC链合约开发教程下载】
- 币安BSC智能链发币教程——通过撤销流动性实现暂停代币交易,设置用户的交易额度实现只允许买入不允许卖出的貔貅币功能【pdf+视频BSC发币教程下载】
- 处理区块链浏览器上uint256类型的数组类型变量中的元素值最大不允许超过1e18长度的限制
- 币安BSC智能链符文教程——defi生态中符文是什么,符文和铭文的区别是什么,怎样部署符文合约【pdf+视频BSC符文教程下载】
- Solidity合约那些常用的技巧
- 币安BSC智能链合约开发教程——LP分红本币的合约处理代码实现,不同时段分红不同数量的本币【pdf+视频BSC链合约开发教程下载】
- AI2.0时代,谁最先赚钱了?
- Sui极简入门,部署你的第一个Sui合约
- 币安BSC智能链合约开发教程——检测到用户成功支付usdt后,执行后续的认购及质押操作【pdf+视频BSC合约开发教程下载】
- Aave V2 逻辑整理
- 智能合约的细粒度暂停
- Solana 开发全面指南:使用 React、Anchor、Rust 和 Phantom 进行全栈开发
- 马蹄Polygon链发币教程——通过metamask跨链桥兑换matic代币【pdf+视频matic马蹄链发币教程下载】
- 如何使用 Circom 和 SnarkJS 实现极简 NFT zkRollup
- arbitrum链上部署合约,实现用户添加流动性获取分红的功能,根据用户持有的流动性LP的权重分红arb代币,同时每笔交易燃烧2%的本币到黑洞地址,基金会钱包地址2%回流arb代币
- ARC20基于BTC网络的新协议,打破BRC20叙事,ARC20挖矿操作教程
- 从合约地址中赎回代币的安全转账函数代码
- 作为Layer2赛道的领跑者,如何理解 Arbitrum?
- 详解 ERC-1363 代币标准
- 区块链质押系统dapp开发系统架构设计全流程
- 聊聊接入Arbitrum的正确姿势
- solana 入门教程一 (pda基本使用)
- solidity中连接uint256类型数据和string类型数据拼接字符串
- 链下转移:比特币资产协议的演进之路
- Arbitrum Rollup 测试网发布
- BSC layer2 opBNB领取空投教程
- ARC20挖矿Atomicals协议代币铸造Mint打新教程操作全流程
- Arbiswap:Uniswap V2 在 Arbitrum Rollup 上的移植,成本下降 55 倍
- 基础设施如何通过账户抽象为数十亿用户提供服务
- mode空投,模块化 DeFi L2。 5.5亿个可用模式。由乐观主义提供动力。
- 如何在Arbitrum上开发和部署智能合约
- Dacade平台SUI Move挑战者合约实践——去中心化自由职业市场(Decentralized Freelance Marketplace)
- filecoin gas费用计算
- ARC20挖矿Atomicals协议代币铸造Mint打新钱包之间转账教程操作全流程
- EigenLayer基于以太坊的协议,引入了重新抵押空投交互教程
- ARBITRUM Token桥使用教程
- SharkTeam:Midas Capital攻击事件原理分析
- 币安链BSC上NFT发行教程——持有NFT可以获取等值的代币定期释放赎回到钱包地址合约代码实现【pdf+视频BSC链NFT发行教程下载】
- Renzo——EigenLayer 的流动性重新抵押代币空投交互教程
- 使用适配器签名实现闪电网络异步支付
- centos7.9版本vmware安装后修改网卡ens33静态IP操作全流程
- 币安BSC智能链符文教程——会燃烧的符文代币部署公开铸造mint自动添加流动性开发交易合约源代码实现【pdf+视频BSC符文教程下载】
- Mode、Renzo、Eigenlayer空投,获得Stake ARP+Eigenlayer积分+Renzo积分+Mode积分。
- Solana SOL链发币教程——solana链上代币添加流动性后实现永久锁仓【pdf+视频SOL发币教程下载】
- 区块链质押挖矿分红奖励dapp开发设计功能需求源码交付运营
- solidity中能否获得当前交易的交易hash值
- 使用适配器签名实现闪电网络异步支付
- 币安BSC智能链合约开发教程——合约层面直接修改资金池中代币余额后同步uniswap账本登记余额【pdf+视频BSC合约开发教程下载】
- Parcl 一种基于区块链的房地产协议积分空投交互获取教程
- BIP 158 致密区块过滤器详解
- 利用Arbitrum和公允排序服务大幅提升DeFi生态的可扩展性,并消除MEV
- bsc链上合约中实现WBNB和BNB进行兑换互转的方式
- solana的getTransaction问题
- DeFi 借贷概念 #2 – 清算
- 币安BSC智能链发币教程——设置买卖不同交易手续费的符文代币合约源代码实现【pdf+视频BSC发币教程下载】
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——Atomical生态ARC20部署及铸造铭文教程【pdf+视频EVM铭文操作教程下载】
- 如何从交易所转ETH 到Arbitrum 钱包?
- ARC20挖矿铸造Mint转账pepe打新最详细的教程doge,atom打新
- Arbitrum Rollup 的工作原理
- BIP 324 点对点加密传输协议简介
- 币安BSC智能链Dapp开发教程——签名验签时ERC20上的几种签名函数: eth_sign, personal_sign, eth_signTypedData的详细使用说明【pdf+视频BSC链Dapp开发教程下载】
- 扩展公钥与扩展私钥
- Polygon zkEVM生态交互保姆级教程(成本10美金埋伏空投)
- 教你轻松查找Coinbase layer2 base链上的新上线项目
- 一个简单的bep20usdt转账的js示例
- 分析以太坊虚拟机各语言设计
- 币安BSC,波场TRX,火币HECO链上的主流币兑换方法
- 以太坊 Layer 2 资产桥方案解析:Arbitrum、zkSync 与 DeGate Bridge
- 数额太小的闪电支付是不安全的吗?
- 投票系统dapp开发流程,前后端以及链端完整代码实现
- 币安BSC智能链Dapp开发教程——ether.js中私钥方式对消息进行签名并实现链端验签,完成系统会员的代币自动充提【pdf+视频BSC链Dapp开发教程下载】
- 币安BSC智能链发币教程——通过合约方式实现USDT批量归集合约部署配置及接口调用【pdf+视频BSC发币教程下载】
- ZK-RaaS网络Opside激励测试网教程(明牌空投)
- 使用solidity语言开发一个支持ERC20协议标准的通证代币全流程
- Arbitrum Nitro 是怎样扩容的以及如何使用它
- DeFi借贷概念 #1 – 借与贷
- 闪电网络中的 “洋葱路由” 及其工作原理
- TP及metamask钱包查询授权记录及取消授权操作方法
- 2024年以太坊layer2最大叙事Blast最低成本撸空投积分(黄金积分),交互dapp操作教程
- redhat双网卡绑定
- 币安BSC智能链Dapp开发教程——web3.js中私钥方式对消息进行签名并实现链端验签,完成系统会员的代币自动充提【pdf+视频BSC链Dapp开发教程下载】
- rust开发solana合约
- 币安BSC智能链发币教程——设置隐藏限制最大累积卖出代币总量的貔貅合约源代码功能实现【pdf+视频BSC发币教程下载】
- redhat下迁移数据库(从文件系统到asm)
- 波场TRX链发币教程——波场链上批量归集USDT的合约代码实现和详细说明【pdf+视频TRX发币教程下载】
- zkPass测试网交互空投资格领取教程
- BRC20、BSC20、ERC20、EVM网络铭文操作教程——ETH链上怎样在swap交易任意数量的eths铭文【pdf+视频EVM铭文操作教程下载】
- centos6.8系统升级glibc版本(升级到 2.17/2.29版)
- TON链(The Open Network)上部署代币并添加流动性实现在线swap交易
- 10.2.0.1g+RAC+裸设备+aix6106+HACMP5.4
- Mode,Renzo和Eigenlayer 一鱼三吃图文教程教程,0成本教程。
- 使用Create2操作码在相同的地址部署不同的代码的合约。
- 币安BSC智能链Dapp开发教程——ether.js中用户交互方式对消息进行签名并实现链端验签,完成系统会员的代币自动充提【pdf+视频BSC链Dapp开发教程下载】
- OptimismPBC vs Arbitrum
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——ATOM本地环境更新教程(保姆级)【pdf+视频EVM铭文操作教程下载】
- Hardhat 开发框架 – Solidity开发教程连载
- 币安BSC智能链Dapp开发教程——web3.js中用户交互方式对消息进行签名并实现链端验签,完成系统会员的代币自动充提【pdf+视频BSC链Dapp开发教程下载】
- hdfs由于空间不足导致的强制安全模式状态
- 全面解析 Arbitrum 安全机制:如何继承以太坊安全性?
- BRC20、BSC20、ERC20、EVM网络铭文操作教程——EVM网络上铭文跨链到WETH的亚合约代码实现【pdf+视频EVM铭文操作教程下载】
- npm 安装软件报报错Getting “Cannot read property ‘pickAlgorithm’ of null” error in react native
- 币安BSC智能链合约开发教程——DEFI合约开发中根据用户买入代币的数量由合约自动撤销对应比率的LP流动性用于分红usdt【pdf+视频BSC链合约开发教程下载】
- Rollups 和 Validium 的“文献综述”
- 币安BSC智能链Dapp开发教程——创建到BSC链的免费provider RPC节点【pdf+视频BSC链Dapp开发教程下载】
- Zookeeper完全分布式集群的搭建一、集群模式
- 史上价值最大规模的空投ZkSync layer2 Airdrop指南
- Solana SOL链发币教程——solana(SOL)链上提交代币元数据metadata信息(名称,简称,描述,logo)【pdf+视频SOL发币教程下载】
- 7 个实时获取加密数据 WebSocket API 头部服务商
- ethscriptions铭文链和哑合约
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——ATOM本地dmint教程【pdf+视频EVM铭文操作教程下载】
- 币安BSC智能链Dapp开发教程——ether.js中对多个变量产生hash值的方式,并添加以太坊前缀【pdf+视频BSC链Dapp开发教程下载】
- solana(SOL)链上如何使用元数据指针扩展简化了向 Mint 帐户添加元数据的过程
- 币安BSC智能链Dapp开发教程——solidity中对多个变量产生hash值的方式,并添加以太坊前缀【pdf+视频BSC链Dapp开发教程下载】
- BRC20、BSC20、ERC20、EVM网络铭文操作教程——EVM网络上铭文部署deploy和批量铸造mint的dapp完整代码实现【pdf+视频EVM铭文操作教程下载】
- Solana SOL链发币教程——solana链上使用nodejs部署带有tokenMetadata(名称,简称,logo,描述信息)的SPL协议标准代币【pdf+视频SOL发币教程下载】
- DeFi借贷概念 #3:奖励
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——ATOM本地Dmint更换节点【pdf+视频EVM铭文操作教程下载】
- solana(SOL)链上使用nodejs与Metaplex Metadata类库交互代码
- 币安BSC智能链Dapp开发教程——ether.js中产生签名消息,solidity端验证签名的实现方式【pdf+视频BSC链Dapp开发教程下载】
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——ATOM的GPU研究【pdf+视频EVM铭文操作教程下载】
- Sushiswap 相关功能模块合约地址记录
- 怎样跟踪Coinbase layer2 Base链上的资金流向,根据资金流向定位优质项目
- 币安BSC智能链Dapp开发教程——html中同时引入ether.js和web3.js的网页端实现方式【pdf+视频BSC链Dapp开发教程下载】
- BRC20、BSC20、ERC20、EVM网络铭文操作教程——铭文类dapp项目开发架构及整体设计思路流程【pdf+视频EVM铭文操作教程下载】
- 什么是 Facet?- 一种以太坊范式的转换
- 币安BSC智能链发币教程——构造函数中直接创建本币对标BNB和USDT的交易对【pdf+视频BSC发币教程下载】
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——Wizz钱包或ATOM钱包更换节点教程【pdf+视频EVM铭文操作教程下载】
- 智能合约安全 – 常见漏洞(第一篇)
- 币安BSC智能链发币教程——可自行燃烧通缩或者授权后代燃烧的ERC20代币燃烧合约代码实现【pdf+视频BSC发币教程下载】
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——Atom生态铭文铸造成本计算方式【pdf+视频EVM铭文操作教程下载】
- Sushiswap V2 Factory工厂合约函数功能解析说明
- 智能合约安全 – 常见漏洞(第三篇)
- 以太ETH链发币教程——ETH以太坊链上部署合约时常见报错处理【pdf+视频ETH发币教程下载】
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——Atomical铸造铭文遇到节点崩溃如何手动广播交易挽回损失教程【pdf+视频EVM铭文操作教程下载】
- 服务器被通过用户弱口令暴力破解并安装比特币挖矿恶意软件后的处理措施
- Hardhat 开发框架 – Solidity开发教程连载
- 币安BSC智能链合约开发教程——dapp中用户触发领取铭文/符文/代币空投后要求用户支付指定数量的WETH进入归集钱包地址代码实现【pdf+视频BSC合约开发教程下载】
- 一段Solidity汇编代码逻辑整理
- Sushiswap V2 pair资金池交易对合约函数功能解析说明
- Create2 创建合约、预测合约地址,看这一篇就够了
- 一篇文章彻底帮助你理解EIP1559之后的Gas机制
- Sushiswap V2 router路由地址合约函数功能解析说明
- Chainlink 2023 年春季黑客马拉松获奖项目公布
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——一键在Ubuntu上运行Bitcoin Atom索引(BTC系列教程2)【pdf+视频EVM铭文操作教程下载】
- 波动率预言机:开启新的DeFi风险管理策略和衍生市场
- Proto-danksharding 是什么以及它是如何工作的
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——ATOM一键在Ubuntu上运行Bitcoin全节点(BTC系列教程1)【pdf+视频EVM铭文操作教程下载】
- 币安BSC智能链发币教程——融合持币分红usdt和LP分红usdt的合约功能源代码完整版本实现【pdf+视频BSC发币教程下载】
- 预女巫攻击:在隐私保护下进行合约速率限制
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——OKX打铭文批量自动连点确认教程【pdf+视频EVM铭文操作教程下载】
- BTC私钥碰撞器(找回钱包丢失私钥)支持比特币BTC标准协议【BTC公链私钥碰撞工具下载】
- 币安BSC智能链Dapp开发教程——直接在网站领取(赎回)代币空投的源代码实现【pdf+视频BSC链Dapp开发教程下载】
- 00_Cairo1.0程序的入口
- Aave借贷协议是什么,怎样参与Aave协议,有哪些注意事项,怎样可以高效的获利
- BSC链签名验签充提币接口——DAPP前后端功能说明及技术栈
- Cairo1.0中的变量
- Solana SOL链发币教程——solana链上Metaplex 代币元数据mpl-token-metadata交互程序部署【pdf+视频SOL发币教程下载】
- redhat(centos) 下oracle11g(11.2.0.4)单机环境搭建DG ASM 多路径
- 实现在项目官网中由用户自行领取代币空投,由用户自己承担所有交易gas费用的功能。写一份solidity链端合约代码实现,并且在web3.js中调用链端,完成代币的赎回空投功能的完整代码
- Cairo1.0中的常量
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——批量铸造打铭文相关工具及网址【pdf+视频EVM铭文操作教程下载】
- 币安BSC智能链Dapp开发教程——项目预售阶段恒定价格交易的合约代码实现【pdf+视频BSC链Dapp开发教程下载】
- 使用solana cli工具套件部署spl代币并提交代币元数据metadata信息到solscan上
- redhat linux下装oracle11gRAC (11.2.0.4)多路经ASM多网卡
- BSC链签名验签充提币接口——node.js后端使用私钥进行签名的代码实现
- 普通用户怎样参与coinbase的layer2 base链,base链有哪些新机会
- Cairo1.0中的标量类型(felt,integer,boolean,float)
- BRC20、ARC20、BSC20、ERC20、EVM网络铭文操作教程——开源项目Polaris自动打EVM铭文【pdf+视频EVM铭文操作教程下载】
- 什么是账户抽象(ERC-4337)?
- Web3初学者教程:什么是区块高度和区块奖励?
- 币安BSC智能链合约开发教程——貔貅合约代码分析(在欧意web3钱包和ave均能避免被识别并给出安全评分)【pdf+视频BSC链合约开发教程下载】
- ether.js中接收solidity合约中返回的多个值的处理方式
- 解读比特币Oridinals协议与BRC20标准 原理创新与局限
- 币安BSC智能链发币教程——USDT批量归集合约部署、开源、参数配置及归集测试全流程操作步骤【pdf+视频BSC发币教程下载】
- NOVA系列之RecursiveSNARK
- 币安BSC智能链合约开发教程——夹子攻击的行为特征,怎样在合约中预防夹子攻击【pdf+视频BSC链合约开发教程下载】
- ether.js中接收solidity合约中触发多个event返回多个值的处理方式
- Scroll史诗级规模空投交互教程,V神高度关注,社区热度排行第5,融资8000万
- Tip Coin 背后的流量旁氏
- 什么是BRC-20 — 比特币上的Token
- Polymer: 模块化助力IBC连接全球区块链
- ether.js中调用连接metamask钱包并获取当前钱包地址、余额、链ID、链名称的代码实现
- 跨链 vs 多链
- SEI空投资格查询 & 申领步骤 & 官方空投细则详解
- 币安BSC智能链发币教程——bsc链上持币分红usdt轮询分发usdt,通过BABYTOKENDividendTracker降低gas费用的源代码实现【pdf+视频BSC发币教程下载】
- 什么是Ordinals?理解比特币 NFT
- 以太坊证明服务 (EAS) 介绍
- 用户自行领取空投的合约功能模块使用说明、部署及开源
- Vitalik: 深入研究用于钱包和其他场景的跨 L2 读取
- 怎样查询链上的TVL及链上热门dapp应用
- Solana SOL链发币教程——Sol链发币教程详解:3分钟创建一个Solana代币合约【pdf+视频SOL发币教程下载】
- ChainTool – 区块链开发者的工具箱 上线了
- 零知识证明, SNARK与STARK 及使用场景
- 初探 Coinbase layer2 Base链 : Base链全新赛道上的潜力项目有哪些?
- Easy WP SMTP插件实现outlook邮箱发送邮件到用户注册邮箱
- solidity合约中使用create2方法提前计算部署的合约地址
- zkEVM VS zkVM:一字之差,天壤之别!
- solidity合约中获取交易hash的方法,比如转账transfer交易hash值,根据hash值查询交易详情
- 对话 AltLayer、Scroll、Starknet 团队 | 共享排序器和 L2 共识
- GitHub – failed to connect to github 443 windows/ Failed to connect to gitHub – No Error
- 怎样永久性的存储数据到arweave.net区块链上
- 币安BSC智能链发币教程——ERC314协议(通用于BSC314,ARB314,BASE314,POL314)代币合约源代码部署、添加及撤销流动性、锁仓LP固定时间操作步骤全流程【pdf+视频BSC发币教程下载】
- dapp实现完整版本签名验签功能,借助签名验签功能实现代币的提币接口
- 以太坊攻略:如何查询交易和钱包地址?
- 区块链浏览器上输入地址类型数组变量作为输入参数时TRC20和ERC20的区别
- BTD存储公链 —— 历时三年新加坡比特米基金会重金,火爆来袭
- 我的微信
- 这是我的微信扫一扫
-

- 我的电报
- 这是我的电报扫一扫
-





