
- A+

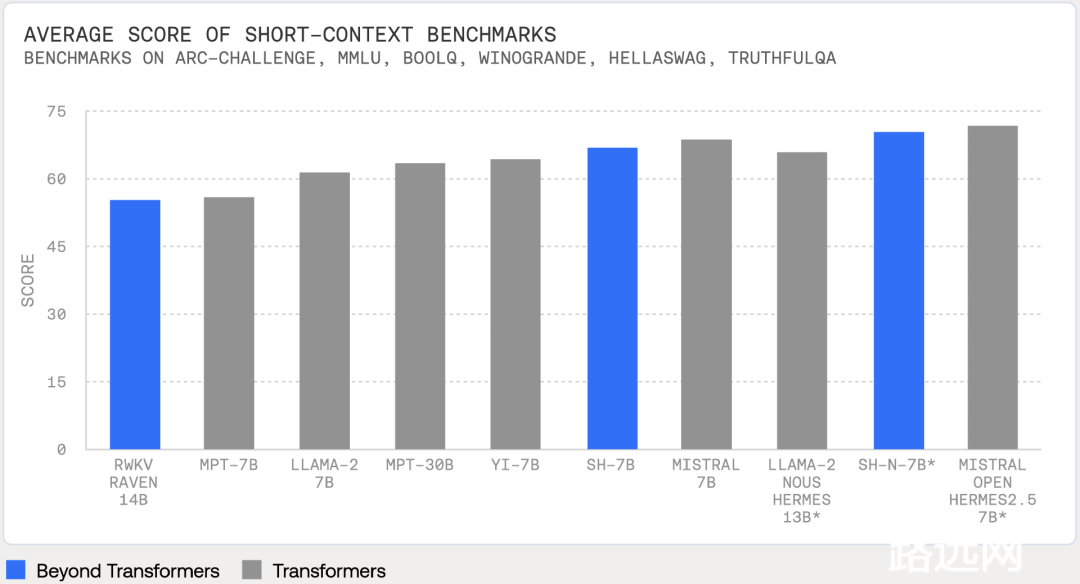
StripedHyena也是「首个」在短上下文和长上下文评估中,以相同模型尺寸,实现了与最佳开源Transformer模型性能相匹敌的模型:在OpenLLM基准任务上与Llama-2, Yi和Mistral 7B实现了相当的性能,并且在长上下文摘要上表现更出色。
StripedHyena是一种混合架构,由多头、分组查询注意力和排列在Hyena块中的门控卷积组成,不同于传统的decoder-only的Transformer:通过将卷积表示为状态空间模型(SSM,state-space model)或截断滤波器,在Hyena块中进行常数内存解码。
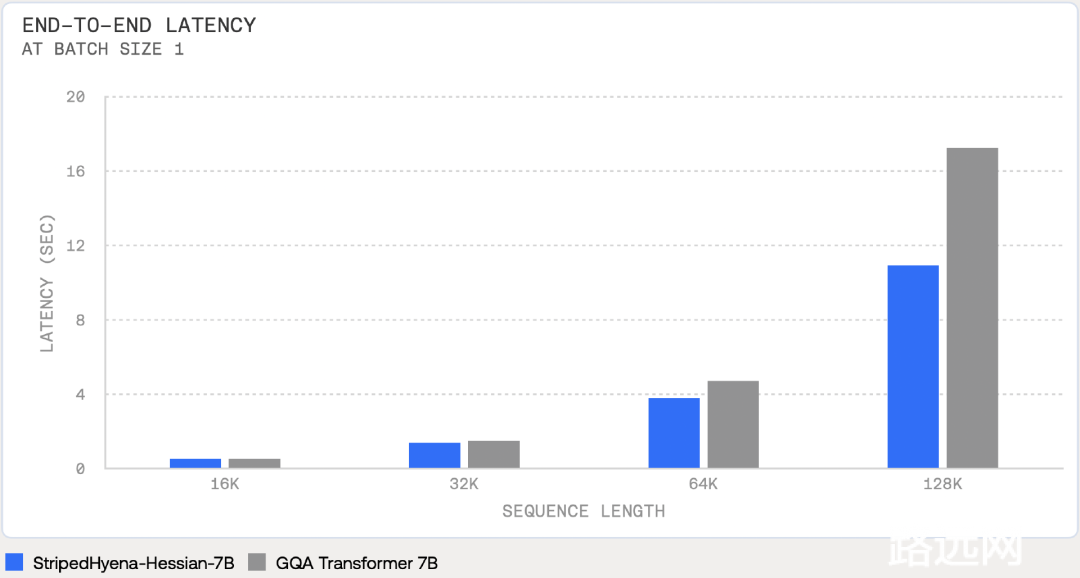
实验结果显示,StripedHyena在32k个token、64k个token和128k个token序列的端到端训练中比传统transformer快30%、50%和100%以上。
SH 7B的另一个优点是,与Transformer相比,自回归生成期间的内存占用减少了50%以上;在Transformers中,每个层的键和值在预填充阶段被缓存,以避免重新计算并加快增量解码。

Hyena块
现有的基于低秩和稀疏近似的次二次(subquadratic)方法需要与稠密的注意层相结合才能匹配Transformer,也就是说二者在表达能力上存在差距。
也就是说,注意力机制在语言处理中只利用了其二次方能力的一小部分,所以研究问题在于,是否存在一个次二次算子,在大规模训练时的性能可以与注意力机制相匹敌?
今年2月,来自斯坦福大学和蒙特利尔大学(Mila and Université de Montréal)的研究人员提出了一个次二次下降的注意力替代品Hyena:在对数千到数十万个token的序列进行召回和推理任务时,Hyena比依赖于状态空间和其他隐式和显式方法的运算符提高了50多个点的准确性,匹配基于注意力的模型。

论文链接:https://arxiv.org/abs/2302.10866
研究人员在标准数据集(WikiText 103和The Pile)的语言建模上设置了一个新的免密集注意力架构,达到了Transformer的质量,在序列长度为2k时所需的训练计算减少了20%;在序列长度为8k时,Hyena算子的速度是高度优化注意力的两倍,在序列长度为64k时,速度快100倍。
研究人员对高效次二次primitive进行组合,如元素乘法(门控)和长卷积(即滤波器大小与输入一样长的卷积),最终从实验结果中得到了肯定的答案。
根据最近在机制可解释性方面所做的工作(如召回recall和归纳induction),研究人员制定了一系列有针对性的推理任务,以提炼出注意力与其性能相关的三个特性,以及与现有次二次元方法之间的质量差距:
1. 数据控制(Data control)
注意力机制实现了一种富有表现力的数据控制线性算子,在单个块中对整个线性函数族进行编码。
2. 次线性参数缩放(sublinear parameter scaling)
将注意力层的参数数量与序列长度脱钩,允许Transformers在注意力层之间的其他地方分配更多参数,例如前馈神经网络(FFN)。
3. 无限制的上下文(unrestricted context)
对于给定的输入,注意力具有不受限制的上下文,可以近似任意两个输入之间的依赖关系,而不受任意限制,如局部性(locality);但使用掩码的情况除外,如自回归模型。
Hyena层次结构
基于上述三个发现,研究人员提出Hyena层次结构,由两个高效的二次基元递归定义的算子(长卷积和元素乘法门控)组成。
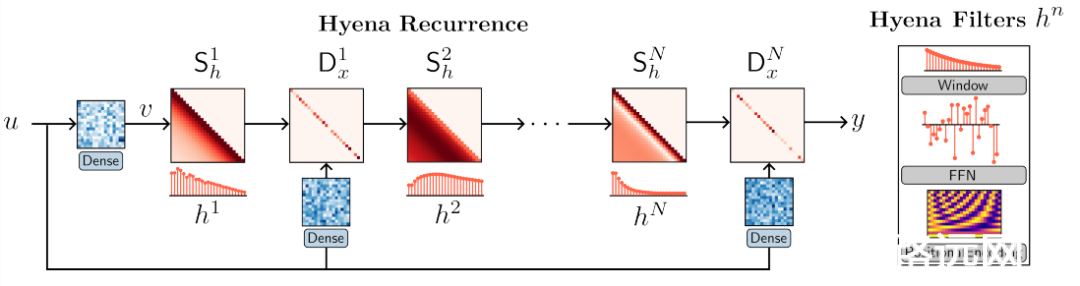
递归的指定深度(即步数)可控制算子的大小;对于短递归,现有模型可作为特例。
通过将 Hyena 递归中的每一步映射到相应的矩阵形式,研究人员发现Hyena算子可以等价地定义为数据控制矩阵的分解,即entries为输入函数的矩阵。
此外,研究人员还展示了如何利用快速卷积算法,在不具体化全矩阵的情况下高效地评估 Hyena 算子。
从经验上看,Hyena 算子能够显著缩小与大规模注意力的质量差距,以更少的计算成本实现了相似的困惑度和下游性能,而且无需混合注意力。
缩小能力差距
设计Hyena的初衷是「标准稠密注意力」和「次二次运算符」之间的存在质量差距,并且可以通过与大规模语言建模性能相关的推理任务来确定这一差距。
研究人员扩展了一套基本的机械可解释性基准(归纳和召回),并增加了额外的任务以探究当任务复杂度增加(如词汇量增加)时,模型性能会如何快速下降。
此外,文中还研究了 Hyena 中长卷积的最佳参数化。
在具有数十万词条的最具挑战性的设置中,隐式参数化方案比其他利用状态空间、频域参数化或标准卷积的算子提高了50%以上的准确率。
语言和视觉中的扩展
研究人员还验证了推理基准套件中的排名是否能预测大规模质量,对Hyena 自回归语言建模进行了十亿以下参数规模的测试,在标准数据集(WikiText103 和 The Pile)中的无稠密注意力架构中实现了新sota,并与Transformer的质量相当。
在3.35亿参数规模的The Pile数据集上,该系统以减少20%浮点运算(FLOPs)总数达到了与Transformer相当的困惑度指标。
作为扩展,研究人员在大规模图像识别中测试了Hyena运算符的通用性,并在视觉Transformer(ViT)中取代了注意力。
在图像分类中,当在ImageNet-1k数据集上从头开始训练时,Hyena 的准确率可以与注意力相媲美。
面向更长的上下文
研究人员还对 Hyena 在长序列上的效率进行了基准测试。在长度为 8192 的序列上,测得的速度是稠密自注意力的 5 倍,是高度优化的 FlashAttention的 2 倍,而在长度为 64k 的序列上,测得的速度是 FlashAttention 的 100 倍。
- 我的微信
- 这是我的微信扫一扫
-

- 我的电报
- 这是我的电报扫一扫
-





