
- A+

昨天,Meta、纽约大学的研究者用「自我奖励方法」,让大模型自己生成自己的微调数据,从而在 Llama 2 70B 的迭代微调后超越了 GPT-4。今天,英伟达的全新对话 QA 模型「ChatQA-70B」在不使用任何 GPT 模型数据的情况下,在 10 个对话 QA 数据集上的平均得分略胜于 GPT-4。
一年多来,ChatGPT 及后续产品引发了生产和研究社区中构建问答(QA)模型的范式转变。尤其是在实际应用中,QA 模型在以下情况成为首选:
- 用户能够以对话方式与 QA 模型进行交互,并可以轻松提出后续问题;
- 通才模型能够以零样本方式生成答案,无需针对数据集进行微调,同时媲美微调专家模型的准确度;
- QA 模型能够在开放域或长文档设置中集成检索到的证据块,提供的上下文比 LLM 的上下文窗口长得多。
不过对于研究界而言,构建一个能够媲美 GPT-4 等 SOTA 黑箱模型准确度的对话 QA 模型仍是一个巨大挑战。
近日,在英伟达的一篇论文中,研究者提出了一个具有 GPT-4 级别准确度的白箱对话 QA 模型 ChatQA 70B。他们采用了两阶段指令调优方法以及用于对话 QA 的 RAG 增强检索器、严格的数据管理过程。

- 论文标题:ChatQA: Building GPT-4 Level Conversational QA Models
- 论文地址:https://huggingface.co/papers/2401.10225
- 论文标题:ChatQA: Building GPT-4 Level Conversational QA Models
具体来讲,本文主要做出了以下贡献:
- 提出了两阶段指令调优方法和数据集管理方法,它们大大增强了 LLM 在零样本对话 QA 任务中集成用户提供或检索上下文时的能力。本文方法显著优于常规指令调优或基于 RLHF 的方法(如 Llama-2-Chat)。
- 对于对话 QA 中的 RAG,展现出了在人类标注多轮 QA 数据集上微调 SOTA 单轮查询检索器的效果与使用基于 LLM 的 SOTA 查询重写模型(如 GPT-3.5-turbo)一样好。
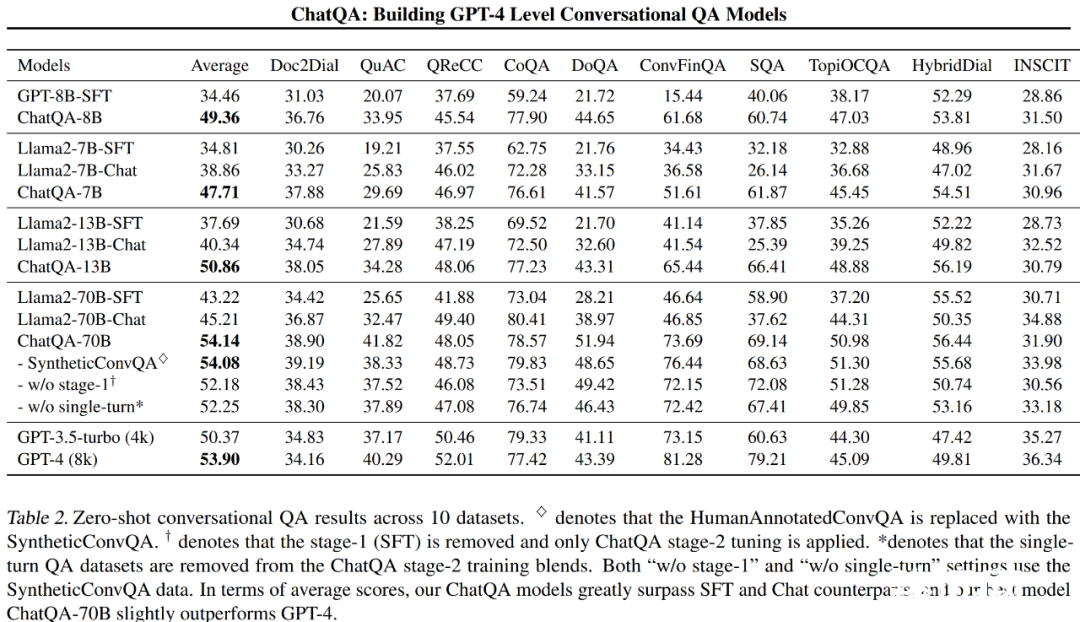
- 基于 Llama2-7B、Llama2-13B、Llama2-70B 和内部 8B 预训练 GPT 构建了一系列 ChatQA 模型,并在 10 个对话 QA 数据集上进行了全面研究,包括 5 个需要检索的长文档数据集和 3 个带有表格的数据集。从平均得分结果来看,ChatQA-70B 可以在不使用任何来自 ChatGPT 模型的合成数据情况下优于 GPT 3.5-turbo (50.37) 和 GPT-4 (53.90)。
- 探究了「无法回答」的场景,即所需要的答案不在提供或检索的上下文中,因此 LLM 很容易产生幻觉。本文证明,在指令调优中添加少量「无法回答」的样本可以引导模型在必要时生成「无法回答」的输出,从而大大减少幻觉。ChatQA-70B 在这方面优于 GPT-3.5-turbo,但与 GPT-4 相比仍有轻微差距(约 3.5%)。
对于英伟达的全新对话 QA 模型,有人认为有趣的一点在于,它不依赖任何来自 OpenAI GPT 模型的合成数据。而像马斯克旗下 xAI 的聊天机器人 Grok 使用了大量 OpenAI 的模型数据。
推特 @fahirmdz
不过,也有读者对英伟达不提供模型权重和代码的做法「很不感冒」。如果这些都不公开的话,再厉害也对 LLM 社区没啥意义。

推特 @AiBeginners
方法细节
ChatQA 两阶段调优
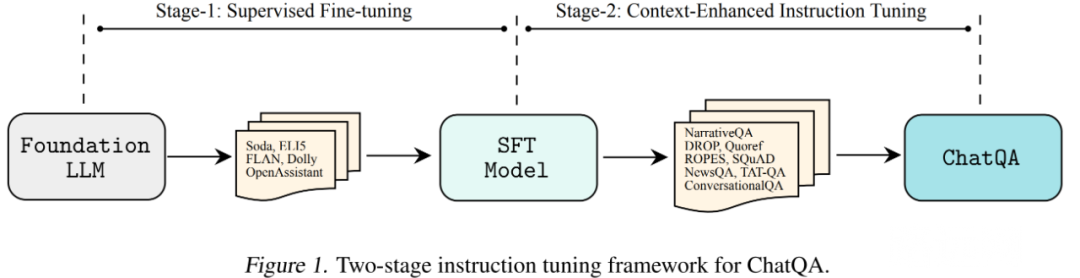
研究者提出了一种用于 ChatQA 的两阶段指令调优方法,请参见图 1。研究者的方法从预训练的 LLM 基础模型开始。在阶段 1,研究者在指令遵循和对话联合数据集上使用了监督微调(SFT)。之后,本文的模型表现出作为对话智能体遵循指令的良好能力。然而情境化或基于 RAG 的 QA 能力仍然有限。
因此,研究者引入了一个称为上下文增强指令调优的后续阶段,它是专门为增强本文模型在对话 QA 中进行上下文感知或检索增强生成的能力而设计的。
多轮问答检索
在对话问答任务中,当文档变得过于冗长而无法直接输入 LLM 时,能够处理对话式查询的检索器就变得至关重要。这种对话检索器会对对话历史和当前查询进行编码,然后从文档中检索相关上下文。之后,只有相关上下文才会被用作 LLM 的输入。最先进的检索器都是针对单轮查询进行优化的,因此对多轮对话查询的泛化能力有限。
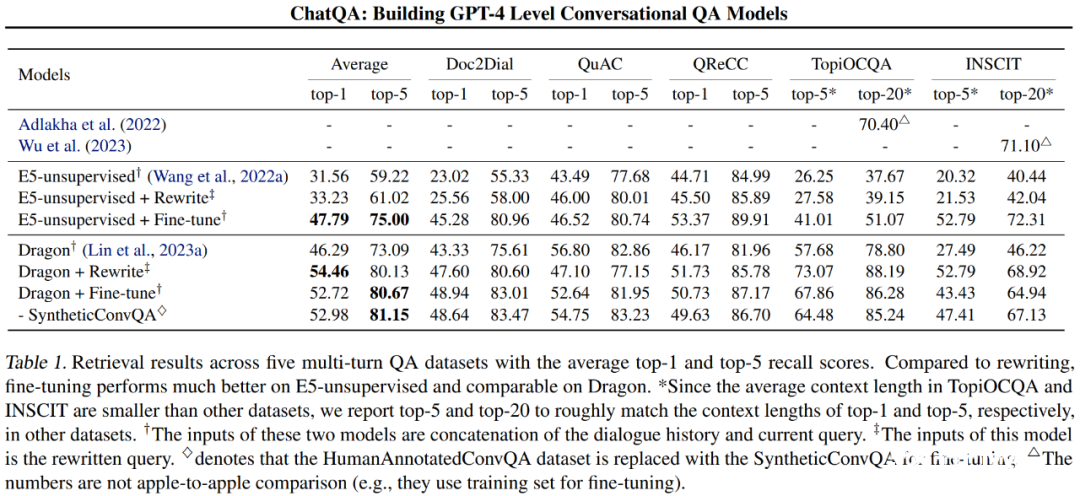
在图 2 中,研究者描述了他们的检索器微调方法,以缓解这一问题。他们建议使用对话查询和上下文对来进一步微调单轮检索器,以更好地应对对话输入。

另一种解决方案是对话查询重写法,它使用查询重写器根据对话历史记录重写当前问题。重写后的查询直接作为单轮查询检索器的输入,用于检索相关上下文。除了嵌入和搜索成本外,查询重写模型还引入了大量额外的计算开销来生成重写后的查询。
在表 1 中,研究者比较了五个数据集在零样本设置下的查询重写和微调方法。
实验及结果
实验设置
研究者在不同规模的模型上进行了实验。首先,为了显示第二阶段上下文增强指令调优的有效性,研究者将 Llama2-SFT7B/13B/70B 与第一阶段监督微调(SFT)后的 Llama2-7B/13B/70B 基础模型进行了比较。其次,与 Llama2-Chat-7B/13B/70B 进行比较,因为 Llama2-Chat 模型被证明具有强大的指令遵循和对话问答能力。
除了 Llama2 模型外,研究者还对自家的 GPT-8B 基础模型进行了实验,并与其第一阶段的 SFT 基线(GPT-8BSFT)进行了比较。最后,还与两个非常强大的 OpenAI 模型进行了比较:GPT-3.5-turbo (4k) 和 GPT-4 (8k)。
为了进行公平比较,研究者使用相同的上下文作为模型和基线的输入。他们对所有基线的指令都进行了仔细调整,以确保它们取得尽可能好的结果。
研究者收集了五个包含长文档的对话式问答数据集。他们将 Doc2Dial、QuAC 和 QReCC 文档分割成大约 300 字的块,并检索前 5 个相关块作为每个用户问题的上下文。对于 TopioCQA 和 INSCIT,研究者遵循它们原始的分割方式,得到了更小的文本块。
为了增加文档长度的多样性,研究者还收集了五个包含短文档(少于 1500 字)的对话式问答数据集。平均而言,每个单词将被分解为 1.5K 个 tokens。这些数据集包括 CoQA、DoQA、ConvFinQA、SQA 和 HybridDial。
考虑到 F1 分数是评估问答模型最常用的自动指标,研究者对 ConvFinQA 之外的所有数据集使用它。在 ConvFinQA 中,研究者使用精确匹配指标,因为 ConvFinQA 中的答案涉及从文档中提取数字以及进行算术计算。因此,只有当答案与标准答案完全相同时,它才有意义。当模型生成算术公式时,研究者将使用计算器计算其最终结果,并与标准答案进行比较。此外,他们还进行了人工评估,以评估他们的最佳模型和 GPT-4 生成答案的正确性。
实验结果
如表 2 所示,研究者比较了不同的模型变体和 OpenAI 模型在 10 个对话式问答数据集上的表现。
他们移除了微调阶段的第一阶段 SFT,仅在基础 LLM 上应用第二阶段的上下文增强指令调优。观察数据可以发现平均得分下降了 1.9(从 54.08 降至 52.18)。除了 SQA 数据集外,移除第一阶段会使模型在其他数据集上的表现一致地变差。
结果表明,即使在第二阶段指令调优中也融合了第一阶段 SFT 的所有数据集,第一阶段仍然扮演着重要角色。因此,研究者认为先建立遵循指令的能力对第二阶段的调整是有益的。
10 个数据集的人类评估结果如表 3 所示。首先,在大多数情况下(占比 69.09%),ChatQA-70B 模型和 GPT-4 表现相当。而 GPT-4 在胜率上略高于本文模型,大约高出 3.3%。这进一步证明了其模型在提供正确答案方面具有强大的能力。其次,在 ConvFinQA 任务中,本文模型比 GPT-4 有略微更好的胜率,这显示了该模型在算术计算方面的强大能力。第三,GPT-4 在 SQA 任务上的胜率明显更高,这表明在表格推理任务上,本文模型与 GPT-4 之间仍存在一定差距。

表 4 中,研究者进一步比较了本文模型和 OpenAI 模型在不同数据集类型的回话问答基准中的表现。

在表 5 中,研究者发现在需要检索的数据集上,使用 top-5 数据块作为训练上下文会带来一些改进。但在非检索数据集上的性能却有所下降。总体而言,这两种模型的性能相当。这是因为在第二阶段的调整中加入了 top-5 检索数据块,使其与需要检索的推理阶段保持一致,从而提高了 Avg-ret 分数。

表 6 展示了关于检索上下文 / 语块数量、上下文排序和不同检索器如何影响对话质量保证结果的消融研究。

表 7 展示了本文模型与 OpenAI 模型在 QuAC 和 DoQA 数据集上进行了比较。
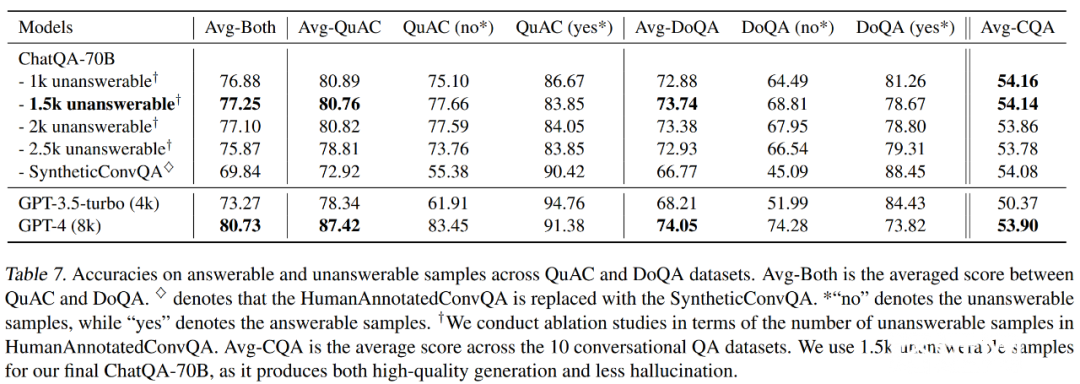
表 8 显示了 ChatQA-70B 和 GPT-4 输出的四个示例。

第一个例子是一个简单的信息寻求问题,ChatQA-70B 和 GPT-4 都给出了正确的答案。在第二个例子中,模型需要找到隐含信息(以蓝色高亮显示)来给出答案。GPT-4 在给出答案时倾向于保守,它回答说上下文没有提供关于年龄的确切信息,这也是正确的。
第三个和第四个例子都要求模型具有良好的表格理解和推理能力。在第三个例子中,ChatQA-70B 通过比较保护区的大小和 3100 公顷给出了正确的答案,而 GPT-4 则未能做到这一点。在第四个例子中,ChatQA-70B 正确列出了三个日期,但漏掉了一个日期,而 GPT-4 则正确回答了这个问题。
- 我的微信
- 这是我的微信扫一扫
-

- 我的电报
- 这是我的电报扫一扫
-





